
数据集成产品分析(一)
编辑导语:数据集成产品是数据中台建设的第一环节,在构建数据中台或大数据系统时,首先要将企业内部各个业务系统的数据实现互联互通,从物理上打破数据孤岛。本文作者对数据集成产品进行了分析,一起来看一下吧。

数据集成产品致力于异构数据源之间的数据交换与汇聚,该类产品是数据中台建设的第一环节,笔者将通过两篇文章对数据集成产品进行分析。
数据同步,又称为数据集成、数据迁移,主要用于实现不同系统间的数据流转。
为什么会有数据同步这类产品?
在企业中,业务的快速发展产生了大量数据,也催生出多种应用系统,各系统承载不同类型的数据,对应着不同的数据存储方式。
而对于构建数据中台或大数据系统,首先需要将企业内部各个业务系统的数据实现互联互通,从物理上打破数据孤岛,而这主要通过数据汇聚和同步的能力来实现。
数据同步方式有多种:API接口同步、数据文件同步和数据库日志解析同步,适用于不同的业务场景。
本次分享的数据同步是基于数据库日志解析的方式实现,其主要应用场景是:数据从业务系统同步到数仓,和数据从数仓同步到数据应用两个方面。
一、数据集成产品简介
1. 产品介绍
数据同步致力于保证数据在不同数据源之间被高效准确地迁移。根据数据时效性要求和应用场景,数据同步可分为离线同步和实时同步:
1)离线同步
主要用于大批量数据的周期性迁移,对时效性要求不高,一般采用分布式批量数据同步方式,通过连接读取数据,读取数据过程中可以有全量、增量方式,经过统一处理后写入目标存储。
成熟的产品有:Sqoop、DataX、kettle等。
2)实时同步
针对数据时效性要求高的场景,其将源端数据的变化实时同步到目标端数据源中,保证源端数据与目标端数据实时保持一致,就可满足业务实时查询分析使用数据或实时计算等需求。
成熟的产品有:Canal、otter等。
在实际业务场景中,离线同步和实时同步搭配使用,为保证已有的数据表在目标端数据源中可用,会使用离线同步将该表的历史数据全量迁移到目标端数据源中,对于增量数据则通过实时集成来增量迁移。
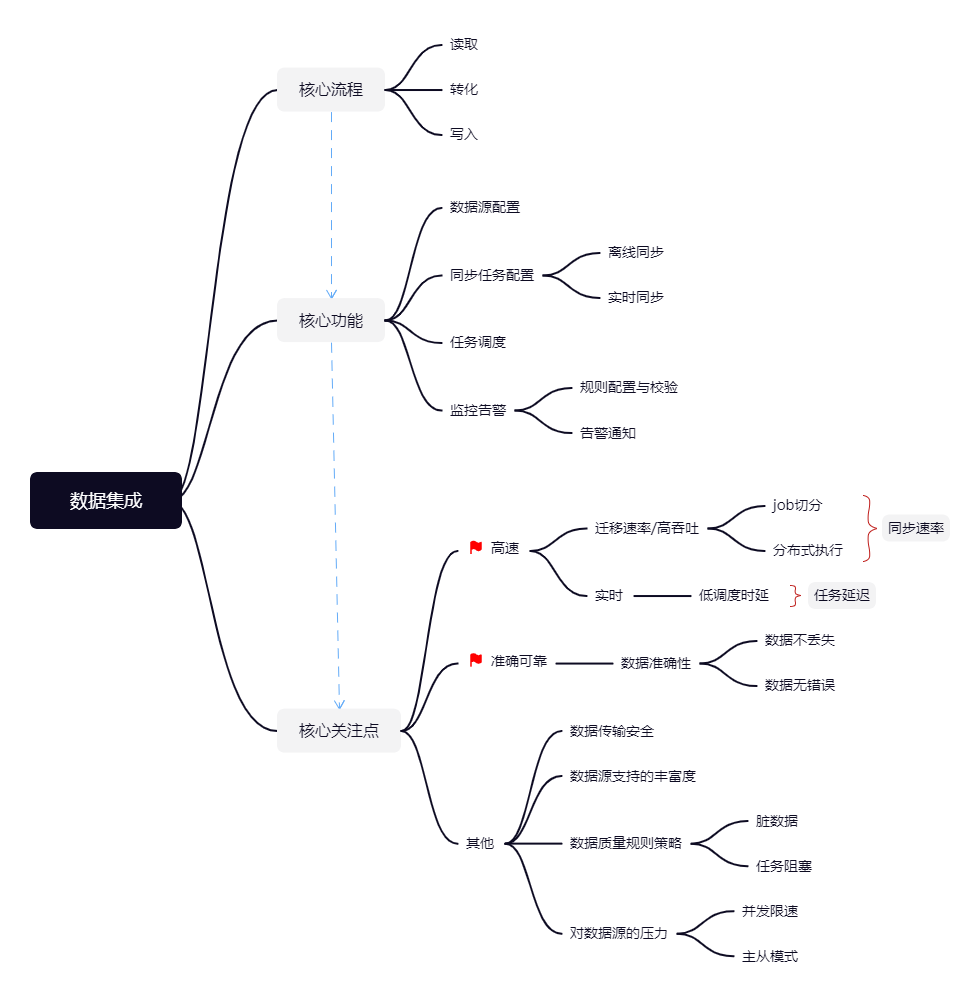
2. 核心流程
数据集成的实现有三个关键步骤:数据读取、数据转换(映射)、数据写入,核心流程如下图所示:
")
具体流程为:数据集成从源端数据源中读取数据,按照建好的映射关系及转换规则,将数据写入到目标数据源中。其中:
- 配置源端数据源和目标端数据源,用于连接数据源,获取数据源的读、写权限等
- 建立映射关系:源端数据源中数据表及字段对应到目标端数据源中的哪张表和字段。建立映射关系后,数据集成根据映射关系,将源端数据写入到对应的目标端数据
- 数据转换规则:数据写入时,可能有不同数据格式转换,敏感数据脱敏展示、无用字段过滤、null值处理等需求,可以制定相应的数据转换规则来实现
- 数据传输通道:可配置任务并发数、数据连接数等任务参数,达到数据集成的任务被高效稳定执行等目的
基于上述流程,数据集成产品的核心功能一般会包含以下4个:
- 数据源配置
- 同步任务配置
- 任务调度
- 监控告警
数据集成平台在进行异构数据源之间的数据迁移时,需要保证迁移任务被高效完成,被迁入目标端数据源的数据是准确可靠的、实时的,数据传输过程是安全的等,这是用户核心关注点,也是期望平台达到的目标。
3. 其他大数据产品的联系和区别
在构建数据仓库的场景中,数据加载到数仓后,随后进行数据加工和数据应用,其中涉及的3类大数据产品如下:
1)数据集成:面向数据汇聚与交换
产品流程:配置数据源—创建同步任务—配置调度任务。
核心任务:ETL、校验、补数、合并。
2)数据加工:面向数据分析
产品流程:创建表—编写加工逻辑(insert)—配置调度任务。
数据加工方式:离线计算、实时计算、机器学习等。
3)任务调度:工作流编排
产品流程:创建任务节点—配置节点依赖关系—提交并执行。
任务调度:任务执行、任务调度与运维。
联系:
- 数据集成和数据加工都是数据生命周期中的一环
- 数据集成任务和数据加工任务其实就是任务调度中的任务节点job,任务调度保证数据被顺序采集和加工出来
以用户画像分析为例,oss_数据同步和rds_数据同步两个节点是数据集成任务节点,ods_log_info_d、dws_user_info_all_d、rpy_user_info_d三个节点是数据加工任务节点,绘制各节点间的连线即工作流编排。
提交并执行画布中的流程节点,数据就会按照箭头方向执行各节点,产出最终结果。
")
区别:数据集成和数据加工都基于任务执行和调度实现,两者虽然都是ETL,但是各自关注的重点并不相同。
①核心动作
数据集成核心动作是抽数(读、写、转换),也就是数据交换,转换动作也只是简单的数据清洗。
数据加工的核心动作是计算逻辑/清洗等加工规则的编写,加工规则复杂。
②核心目标
数据集成的核心目标,是保证数据被高效准确地迁移到目标端数据源。
数据加工的核心目标,是加工规则编写准确“翻译”业务需求。
二、数据集成产品流程
离线集成与实时集成在实际运行中,关注的侧重点是不同的,对于离线集成,面对的是批数据,更多考虑大规模数据量的迁移效率问题;对于实时集成,面对的是流数据,更多考虑数据准确性问题。
数据同步中一般采用先全量在增量的方式来进行数据的迁移,即先将历史数据全量迁移到目标数据源,完成初始化动作,在进行增量数据的实时同步,这样保证目标端数据的可用性。当然也有不care历史数据的场景,此时就无需进行全量迁移的动作。
1. 实时集成
我们主要采用基于日志的CDC方式来实现增量数据的实时同步,CDC即change data capture,捕获数据的变化。
实时集成通过读取源端数据库日志bin_log来捕获数据的变化情况(insert、update、delete),将其传输到kafka topic中,然后通过spark streaming对数据进行转换/清洗,写入到stg增量表中,最后将增量数据与全量数据合并到数仓ods表中。
由于数据库日志抽取一般是获取所有的数据记录的变更(增、删、改),落到目标表时,需要根据主键去重,并按照日志时间倒序排列获取最后状态的变化情况。
具体的实时集成任务执行逻辑及流程如下所示:

实时集成有以下特点:
- 源端数据库产生一条记录,数据集成实时同步一条记录
- 流数据在数据传输过程中可能会被丢失或延迟
故相较于离线集成,在数据同步链路上,实时集成会增加数据校验和数据合并两个动作。
- 数据校验主要校验源端和目标端的数据量,保证数据没有被丢失
- 数据合并则是由ods库base表和cdc目标库increment表组成,具体逻辑为:将stg数据按主键去重,取最新一条,根据主键与ods数据表中的T+1数据合并
2. 离线集成
离线集成分为全量和增量两种方式对大规模数据进行批量迁移。
- 全量迁移是将某些表的全部历史数据同步到目标数据源中
- 增量迁移,通常需要使用where子句(RDB)或者query子句(MongoDB)等增量配置参数,同时在结合调度参数(定时任务的重复周期:分钟、小时、天、周、月等)可实现增量迁移任意指定日期内的数据。
比如,想要实现每日数据的增量同步,各参数可配置为:
- Where子句:配置为DS=’${dateformat(yyyy-MM-dd,-1,DAY)}’,
- 配置定时任务:重复周期为1天,每天的凌晨0点自动执行作业
增量迁移的数据可以对目标端数据源表中数据进行追加、覆盖和更新操作。
作者:细嗅蔷薇,微信公众号:零号产品er
本文由 @细嗅蔷薇 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
白丁学者 » 数据集成产品分析(一)










