
python 一键生成爬虫request请求头信息的2种方法
大家在做爬虫处理时,每次复制的请求头信息都是比较多的,但是无法快速格式化符合python样式,现在通过2种方法,可以节省大家的重复劳动。

【第一种方法】:
通过正则表达式方法快速处理。
(.*?): (.*)
'$1':'$2',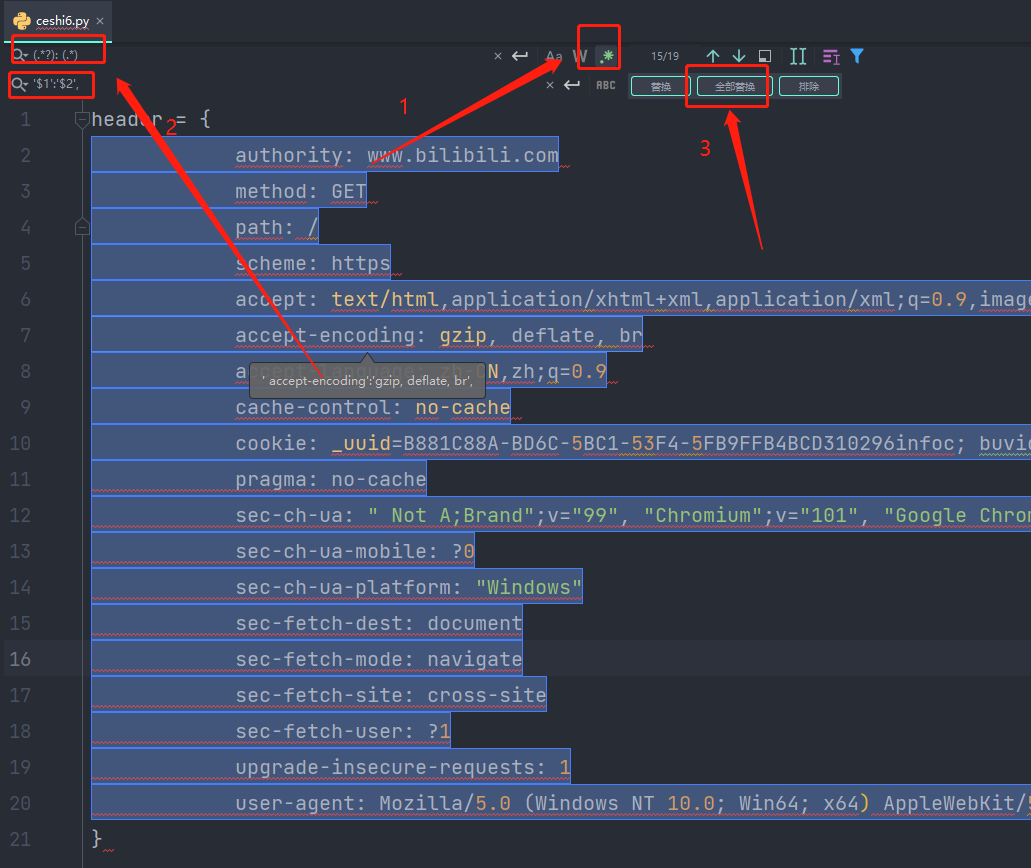

【第二种方法】:
网站在线转换
1,Chrome 打开开发者选项( f12 )—> network 选项卡 —> 刷新页面,获取请求 —> 找到页面信息对应的请求 (通过请求的名称、后缀和 response 内容来判断)
2,右键,copy —> copy as cURL (bash),注意不是【copy as cURL (cmd)】
3,打开网站,https://curl.trillworks.com/,粘贴 cURL (bash) 到左边 curl command,右边会自动出 Python 代码
网站声明:
1.本站大部分资源搜集于网络,仅代表作者观点,如有侵权请提交修改。
2.网站内容仅网站站长做个人学习摘记,任何人不得用于其他商业用途,网站发表的内容全权归原作者所有。
3.有任何疑问,可以点击右侧边栏的联系QQ进行咨询
4.本网站部分内容来自于其他网站平台的,版权归原网站所有,本网站只作信息记录,自己学习使用,特此申明,本站用户也不得使用此信息内容做其他商业用途。
白丁学者 » python 一键生成爬虫request请求头信息的2种方法
白丁学者 » python 一键生成爬虫request请求头信息的2种方法